VoP API Performance Monitoring: Technical Guide for DevOps Teams

Why VoP API Monitoring Is Mission-Critical
When Verification of Payee (VoP) becomes part of your payment infrastructure, your DevOps team inherits responsibility for one of the most critical components in the transaction flow. VoP isn’t just another API endpoint — it’s a regulatory requirement, fraud prevention tool, and customer experience factor all rolled into one.
A slow or failing VoP API doesn’t just mean delayed payments. It means:
- Broken SEPA Instant SLA compliance (10-second transaction limits)
- Manual intervention floods for your operations team
- Regulatory audit complications when compliance checks fail
- Customer frustration when payments are delayed or rejected
For DevOps and SRE teams managing payment systems in Europe, monitoring VoP performance isn’t optional — it’s essential infrastructure hygiene.
The Cascading Impact of VoP Performance Issues
Understanding why VoP monitoring matters requires seeing the bigger picture. When VoP API performance degrades, the effects ripple through your entire payment ecosystem:
Payment Processing Delays: Every millisecond added to VoP response time directly impacts transaction completion time. With SEPA Instant’s strict 10-second limit for complete transaction cycles, VoP latency becomes a bottleneck that can break compliance.
Operational Overhead: VoP failures trigger automatic fallbacks to manual verification processes, flooding support teams with exception handling tasks and breaking automated payment flows.
Compliance Risks: Failed VoP checks create audit trail gaps and regulatory compliance issues, especially as VoP becomes mandatory for instant payments under evolving SEPA regulations.
Essential Performance Metrics Every DevOps Team Must Track
Response Time and Latency Thresholds
For SEPA Instant compliance, your VoP API response times need to be consistently fast:
Target Response Times:
- Average latency: less than 1000ms
- 95th percentile: less than 1500ms
- 99th percentile: less than 2000ms
- Maximum timeout: 3000msMonitor end-to-end processing time, including network overhead, RVM (Reference data Verification Module) processing, and response parsing. Use distributed tracing to identify bottlenecks in the VoP verification chain.
Availability and Uptime Standards
Payment systems demand high availability. Your VoP monitoring should track:
- Monthly uptime target: 99.9% minimum (43.8 minutes max downtime)
- MTTR (Mean Time To Recovery): less than 5 minutes for automatic recovery
- MTBF (Mean Time Between Failures): more than 720 hours
Pay special attention to external RVM provider availability, as their outages directly impact your service but are outside your control.
Error Classification and Analysis
Not all VoP errors are created equal. Your monitoring system should distinguish between:
Client-Side Errors (4xx):
- Invalid request parameters or malformed data
- Authentication/authorization failures
- Rate limiting violations
Server-Side Errors (5xx):
- Connection timeouts and network issues
- Internal VoP provider system failures
- Upstream service dependencies failing
Business Logic Responses:
- “No Match” — payee not found in reference data
- “Close Match” — partial match requiring review
- “Verification Not Possible” — temporary system unavailability
A sudden spike in “Verification Not Possible” responses often indicates problems in the European Directory Service (EDS) infrastructure or local RVM systems.
Load Patterns and Throughput Analysis
Understanding your VoP traffic patterns helps with capacity planning and optimization:
- Temporal patterns: Peak loads during payroll periods, month-end processing, or business hours
- Request types: Ratio of real-time verification to batch processing
- Retry behavior: Impact of retry policies on overall system load
Implement intelligent rate limiting and adaptive retry strategies to prevent cascading failures during peak usage.
Verification Outcome Distribution
Track the distribution of VoP verification results to identify data quality issues and optimize fraud detection:
Key Metrics to Monitor:
- Match Rate: % of exact payee matches
- Close Match Rate: % requiring manual review
- No Match Rate: % of verification failures
- Technical Failure Rate: % of system errorsUnusual changes in these distributions often signal:
- Data quality degradation in input feeds
- Need to adjust fuzzy matching algorithms
- Problems with upstream reference data sources
SLA Requirements and Regulatory Compliance
Meeting Minimum Performance Standards
The EPC VoP scheme and emerging SEPA regulations establish baseline requirements:
| Performance Metric | Minimum Requirement |
|---|---|
| API Availability | more than or equal to 99.9% monthly |
| Average Response Time | less than 1 second |
| Incident Response | less than 5 minutes |
| Log Retention | 6-12 months for audit |
| Recovery Time | less than 15 minutes maximum |
Audit Trail and Compliance Logging
EPC-certified VoP providers must maintain detailed audit trails for regulatory compliance. Your monitoring system should capture:
- Immutable transaction logs with complete VoP request/response cycles
- Trace ID correlation linking VoP operations to payment transactions
- Exportable metrics in formats required by regulators and auditors
This audit data becomes critical during regulatory reviews and internal compliance assessments.
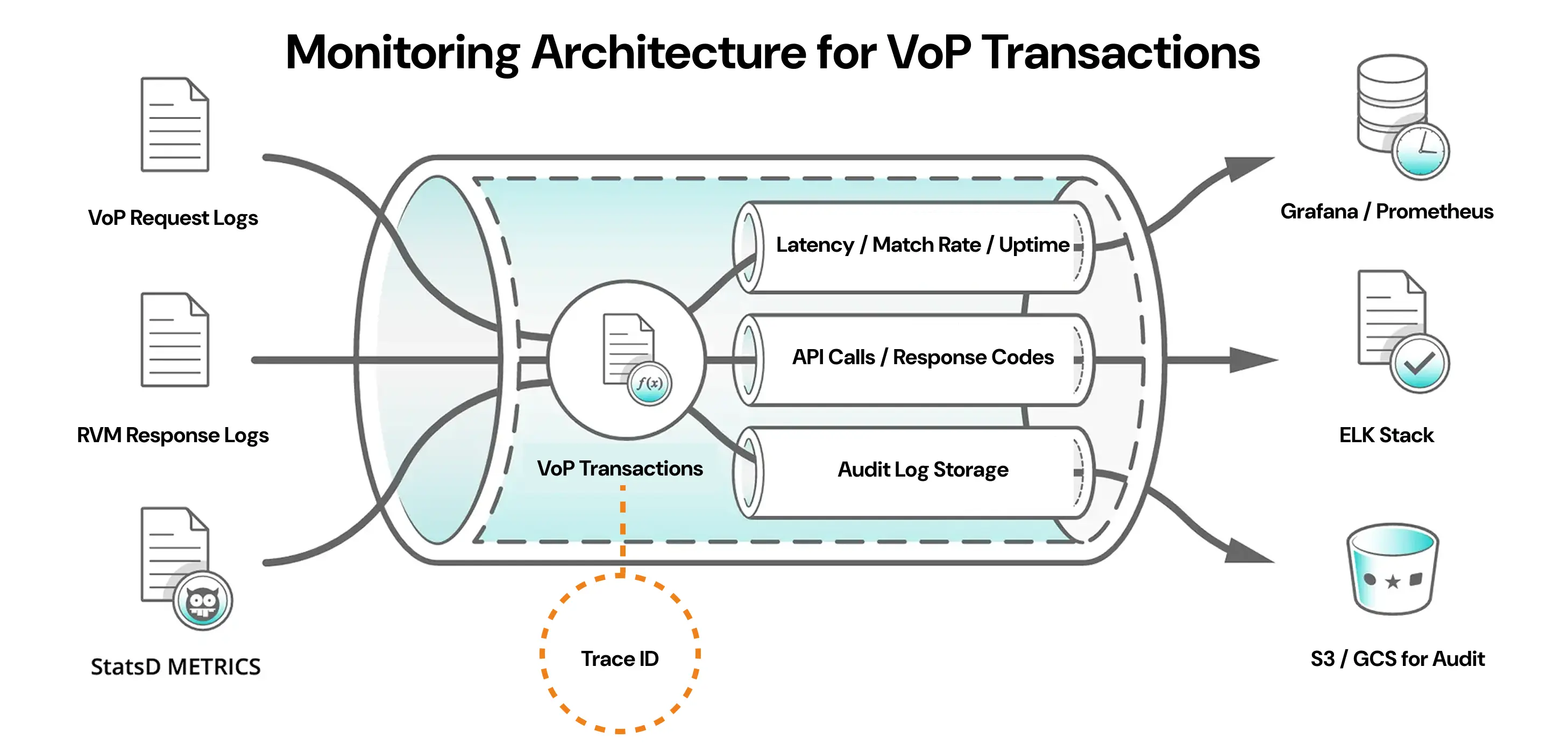
Figure 1: Complete VoP monitoring architecture showing trace ID correlation across all system components
Building a Comprehensive Monitoring Stack
Core Monitoring Infrastructure
Metrics Collection and Storage:
- Prometheus with custom VoP operation metrics and alerting rules
- Grafana dashboards for real-time visualization and historical analysis
- OpenTelemetry for distributed tracing across payment processing pipelines
Centralized Logging:
- ELK Stack (Elasticsearch, Logstash, Kibana) for log aggregation and analysis
- Fluentd for unified log collection from multiple VoP providers
- Structured JSON logging with mandatory fields: trace ID, timestamp, response codes, latency
Incident Management:
- PagerDuty or Opsgenie for automated alerting and escalation
- Multi-tier alerting with different severity levels and response procedures
- Automated runbooks for common VoP failure scenarios and recovery procedures
Testing and Validation
Synthetic Monitoring:
- Continuous health checks against VoP endpoints from multiple locations
- Realistic transaction simulation in test environments
- SLA validation under various load conditions and failure scenarios
Environment Management:
- VoP sandbox access for integration testing and development
- Emulation of all response scenarios (Match, No Match, Close Match, errors)
- Disaster recovery testing with failover procedures
Integration Strategies for Existing Infrastructure
Observability Pipeline Integration
VoP monitoring should integrate seamlessly with your existing observability infrastructure:
Unified Distributed Tracing: Use consistent trace IDs throughout your payment pipeline to correlate VoP operations with upstream payment initiation and downstream settlement processes.
Service Mesh Compatibility: If using Istio, Linkerd, or similar service mesh technology, ensure VoP services are included in your overall traffic management and security policies.
GitOps Deployment: Version control VoP monitoring configurations and deploy them through your existing CI/CD pipelines alongside application code changes.
Fault Tolerance and Resilience
Circuit Breaker Implementation: Automatically disable VoP requests when error thresholds are exceeded, with gradual traffic restoration as service health improves.
Graceful Degradation: Define clear fallback strategies when VoP services are unavailable, such as switching to basic IBAN validation or manual review processes.
Multi-Provider Architecture: For mission-critical systems, implement the ability to failover between multiple VoP providers to maintain service availability.
Performance Optimization Techniques
Intelligent Caching Strategies
Implement smart caching to reduce VoP API load and improve response times:
Positive Result Caching: Cache successful Match results for short periods (5-15 minutes) to handle duplicate verification requests efficiently.
Negative Result Caching: Temporarily cache No Match results to prevent repeated failed verification attempts for the same payee data.
Cache Invalidation: Implement strategies to invalidate cached results when reference data is updated or when cache TTL expires.
Batch Processing Optimization
For high-volume operations, optimize batch VoP processing:
Request Aggregation: Combine multiple individual VoP requests into efficient batch operations where supported by your VoP provider.
Parallel Processing: Process independent VoP verifications in parallel to maximize throughput while respecting API rate limits.
Queue Management: Use message queues to buffer and smooth peak loads, preventing system overload during high-traffic periods.
Practical Implementation Example
Here’s how a typical VoP monitoring setup might look in a production environment:
# Prometheus alerting rules for VoP monitoring
groups:
- name: vop_api_alerts
rules:
- alert: VoPHighLatency
expr: histogram_quantile(0.95, vop_api_duration_seconds) > 1.5
for: 2m
labels:
severity: warning
annotations:
summary: "VoP API 95th percentile latency is high"
- alert: VoPHighErrorRate
expr: rate(vop_api_errors_total[5m]) > 0.05
for: 1m
labels:
severity: critical
annotations:
summary: "VoP API error rate exceeds 5%"This monitoring approach ensures your team catches performance issues before they impact payment processing or regulatory compliance.
Looking Forward: VoP Monitoring Best Practices
Effective VoP API monitoring requires treating verification services as mission-critical payment infrastructure, not external dependencies. Your monitoring strategy should encompass technical performance, regulatory compliance, and operational readiness.
The investment in comprehensive VoP observability pays dividends through:
- Reduced operational risks and faster incident resolution
- Maintained regulatory compliance with automated audit trails
- Improved customer experience through consistent payment processing performance
- Cost optimization through efficient resource utilization and proactive issue prevention
As VoP becomes mandatory for instant payments across Europe, robust monitoring transforms from a technical nice-to-have into a business necessity. Start building your VoP monitoring strategy now — before compliance deadlines make it urgent.
Want help implementing VoP monitoring the right way?
Talk to us - we’ll help you align your observability stack with VoP requirements before compliance becomes critical.